HTTP & MQTT → S3 ingest
The easiest way to land data in S3
Send JSON via HTTP or MQTT. Get Parquet and compressed segments in your S3 bucket. No Kafka, no Kinesis, no glue code.
10 GiB/month free on Starter. No credit card required.
No infrastructure
Data in, S3 out. No brokers, no clusters, no glue code.
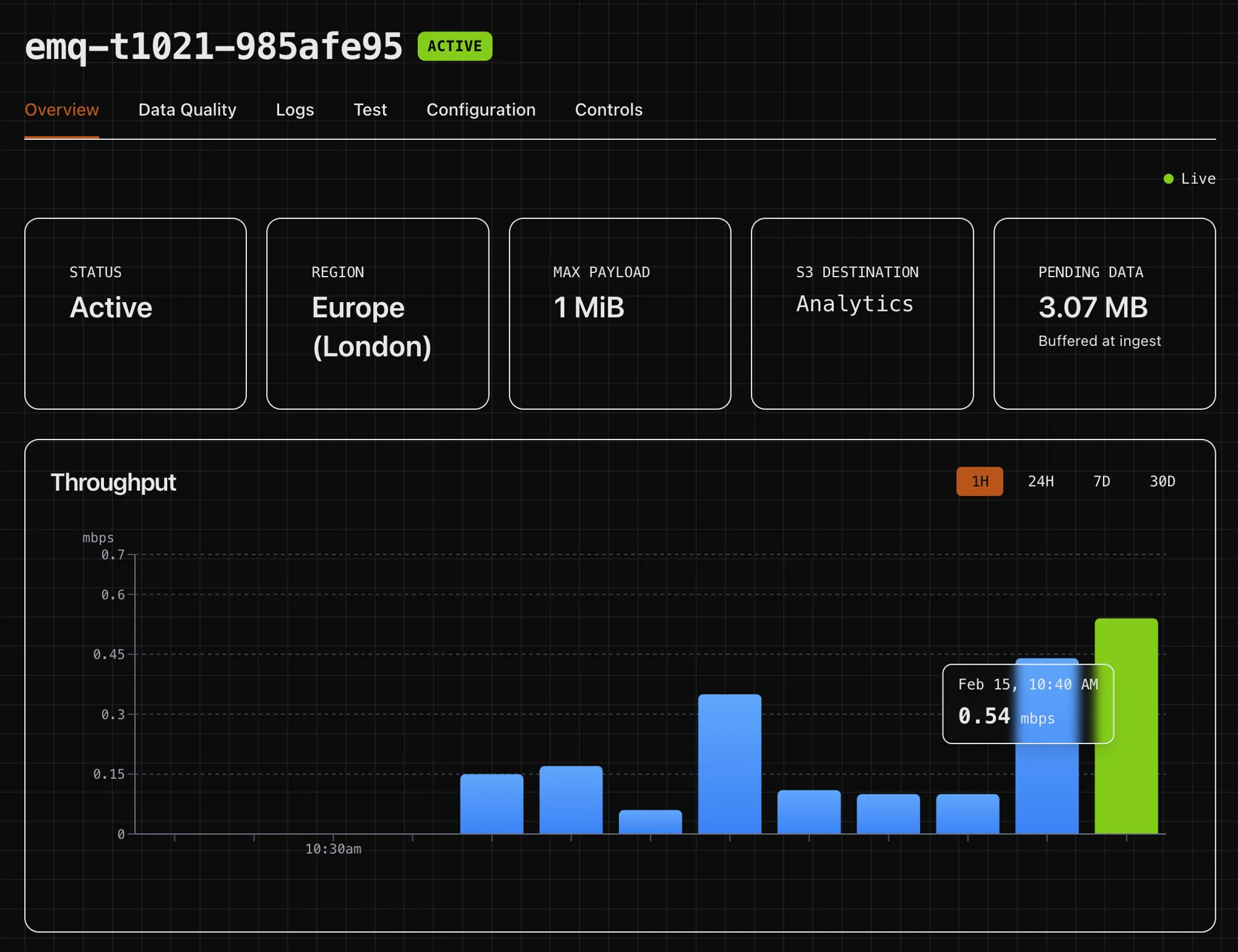
Zero data loss
Every record WAL-committed before acknowledgment. Automatic crash recovery.
Query-ready output
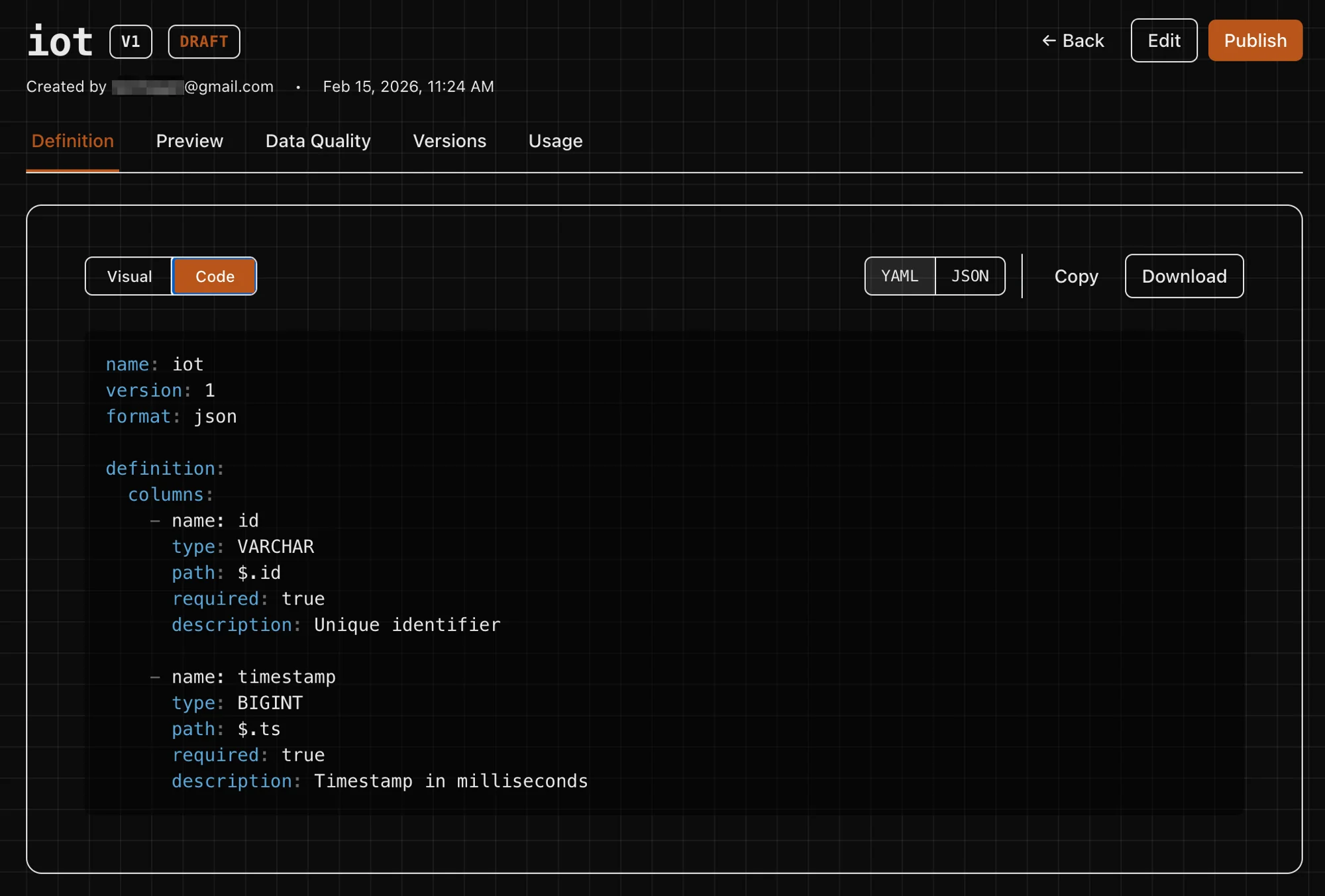
Schema-aware Parquet with type casting, partitioning, and filtering. No ETL pipeline.
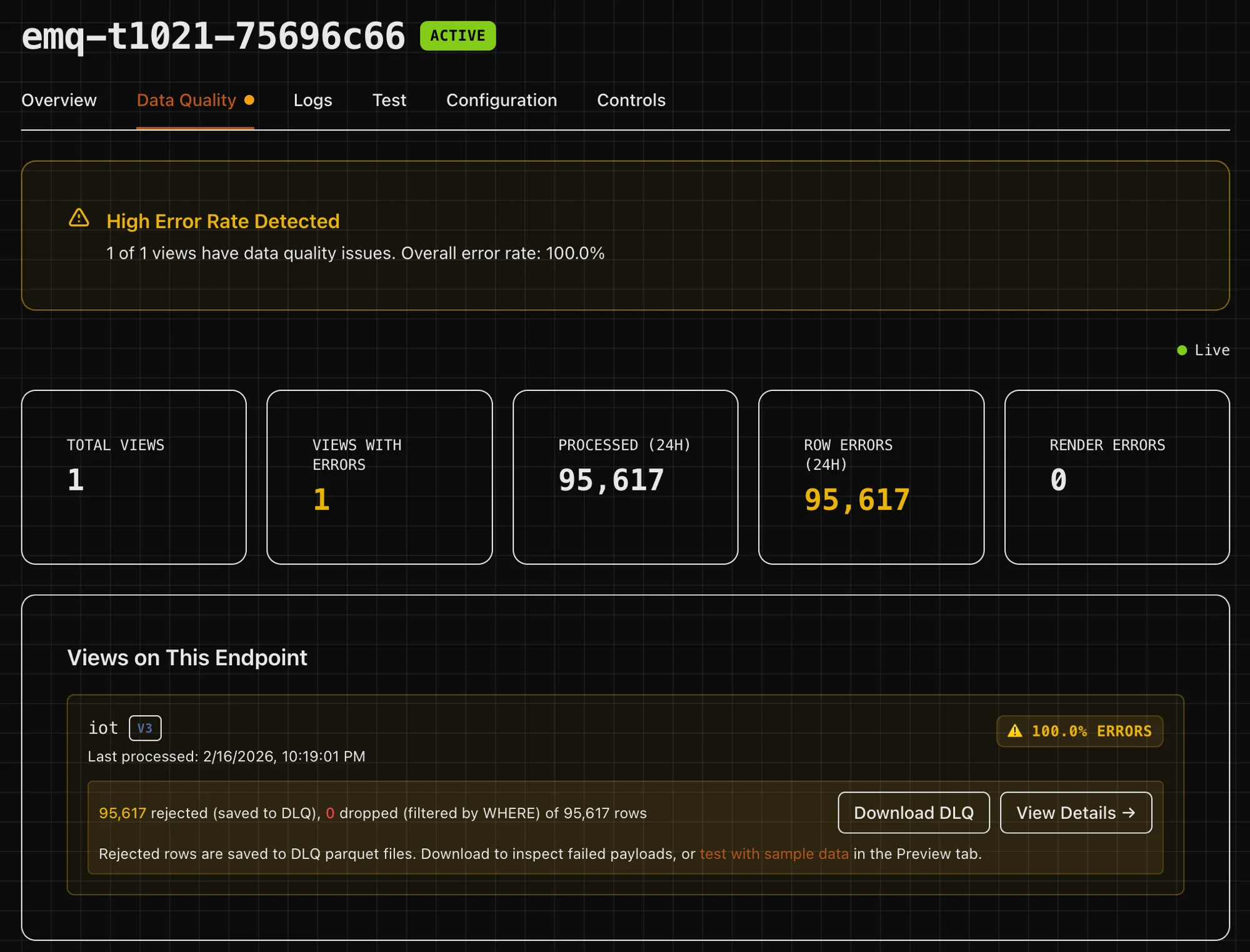
Data quality built in
Dead letter queues, error rate metrics, and schema preview out of the box.
Your storage, your control
Data lands in your S3 bucket, your region, with your encryption keys.
Core features
Everything between POST and Parquet
Your own ingest infrastructure, zero ops.
Each endpoint is a dedicated VM with its own NVMe-backed WAL volume and isolated process boundary. Deploy to any of 15+ global edge locations, and EdgeMQ handles provisioning, autoscaling, rolling updates, and failover automatically.
Performance
Built for speed and reliability
How it works
Ingest, seal, commit
POST /ingest your app ─────────────► EdgeMQ ─────────────► your S3 (NDJSON) (edge) (bucket)
Commit markers tell your jobs what's safe to read.
Simple integration
One call, three output formats
Send NDJSON to your regional endpoint. EdgeMQ handles WAL, compression, and S3 uploads.
curl -X POST "https://lhr.edge.mq/ingest" \ -H "Authorization: Bearer $TOKEN" \ -H "Content-Type: application/x-ndjson" \ --data-binary @events.ndjson
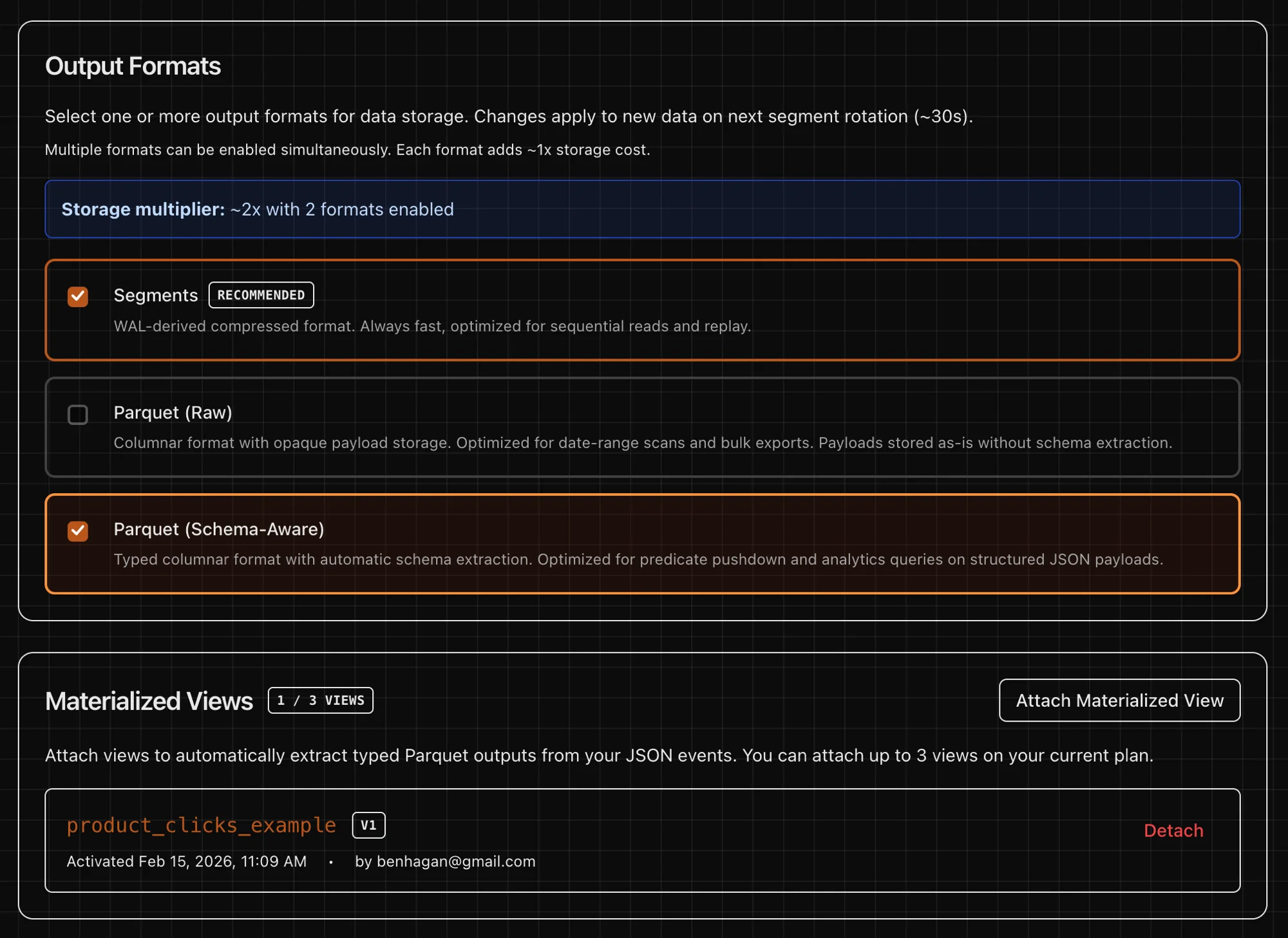
Compressed WAL segments (.wal.zst) plus commit markers. Ideal for archival and raw replay.
Date-partitioned Parquet with full payload preserved. Query with any engine.
Schema-aware typed columns from view definitions. Ready for warehouses and feature stores.
Built for teams that live on S3
From ML pipelines to lakehouse ingest
Simple pricing
Starter is free up to 10 GiB/month. Then $0.10/GiB. Pro starts at $49/month with schema-aware views.
Get data into S3 in under 10 minutes
Create an endpoint, connect your S3 bucket, and start POSTing. Your first Parquet files will land before you finish reading the docs.